Open Source · No API Keys · Easy to Use
Generate AI context files
from any codebase.
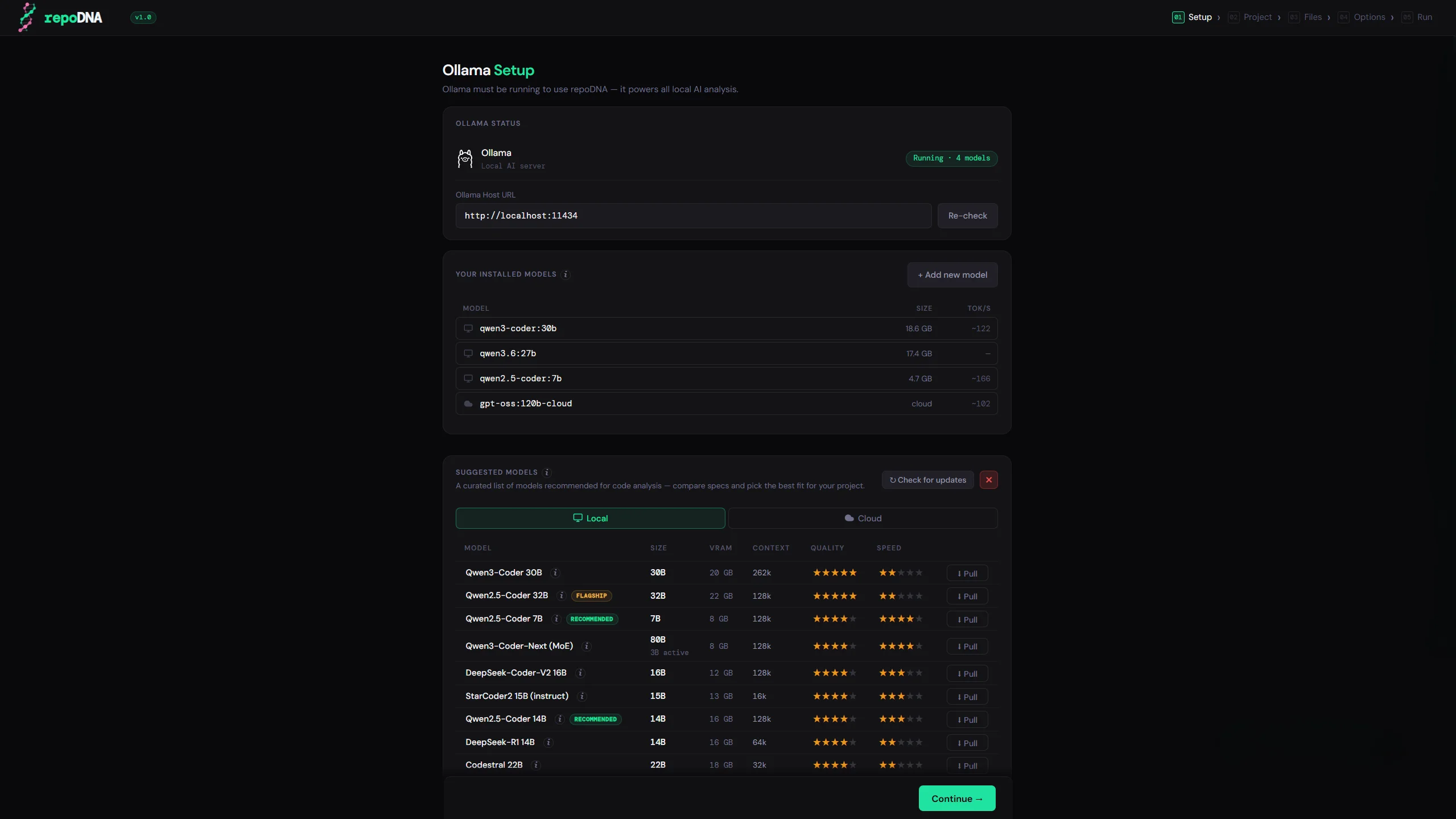
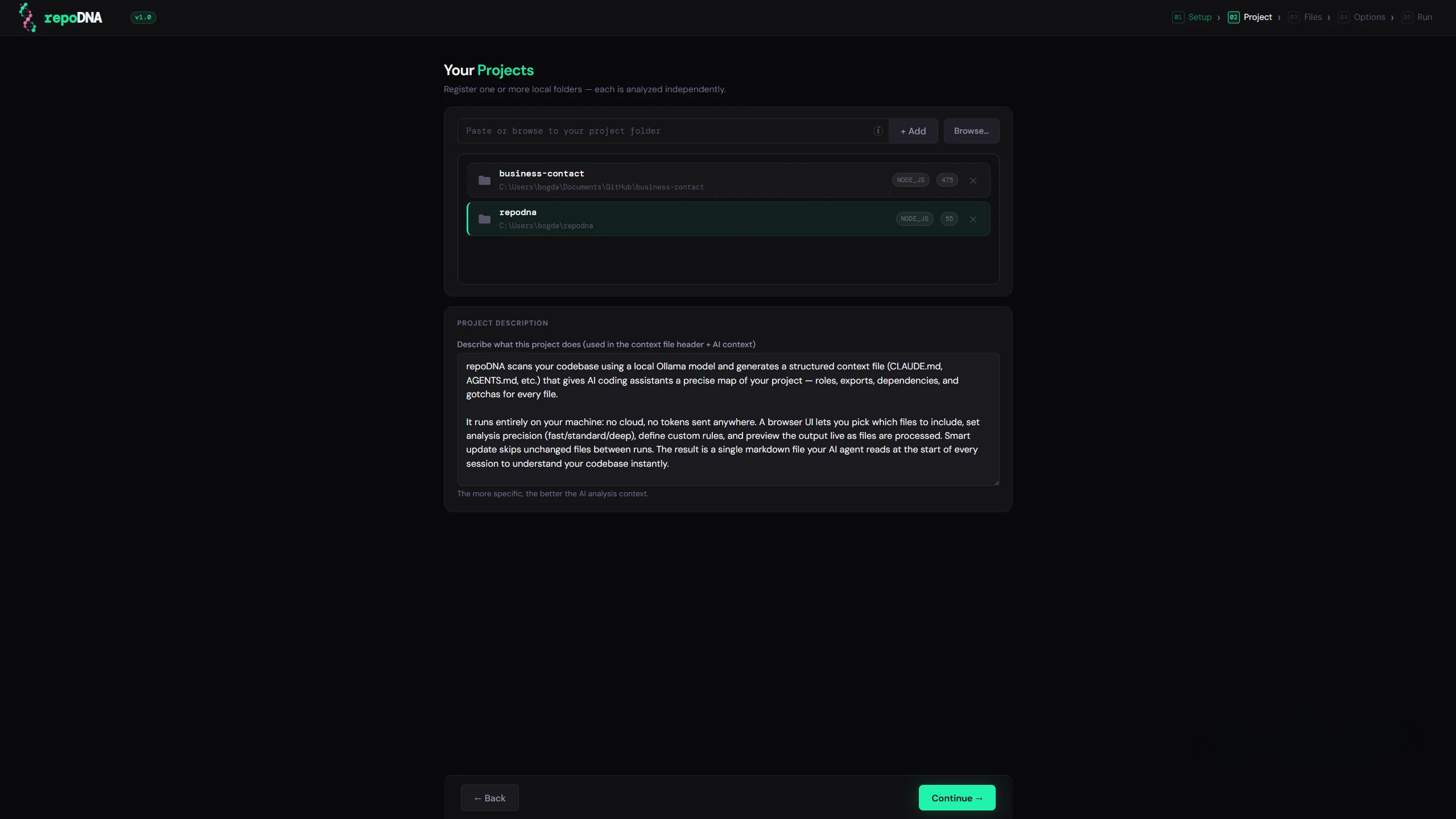
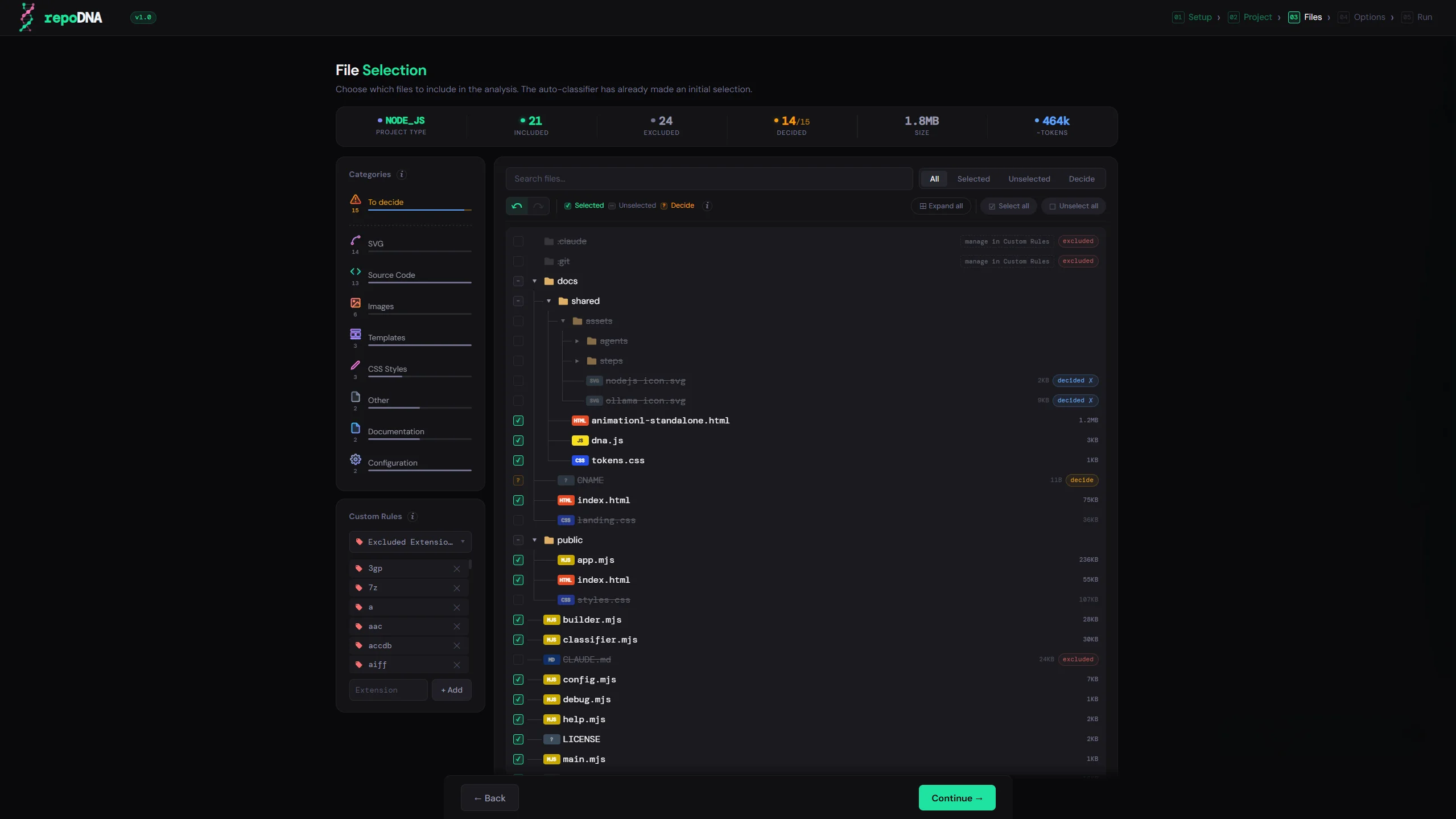
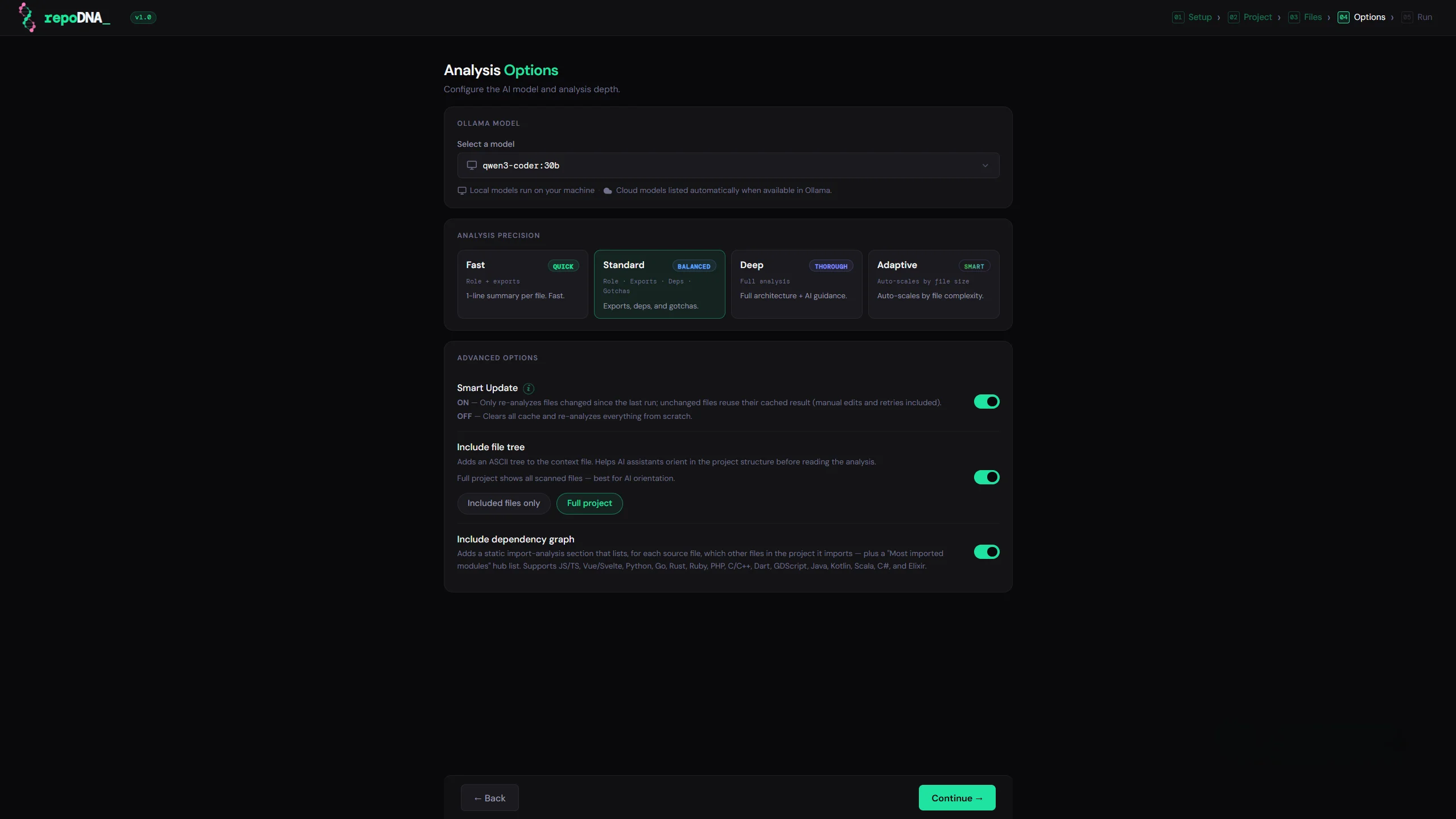
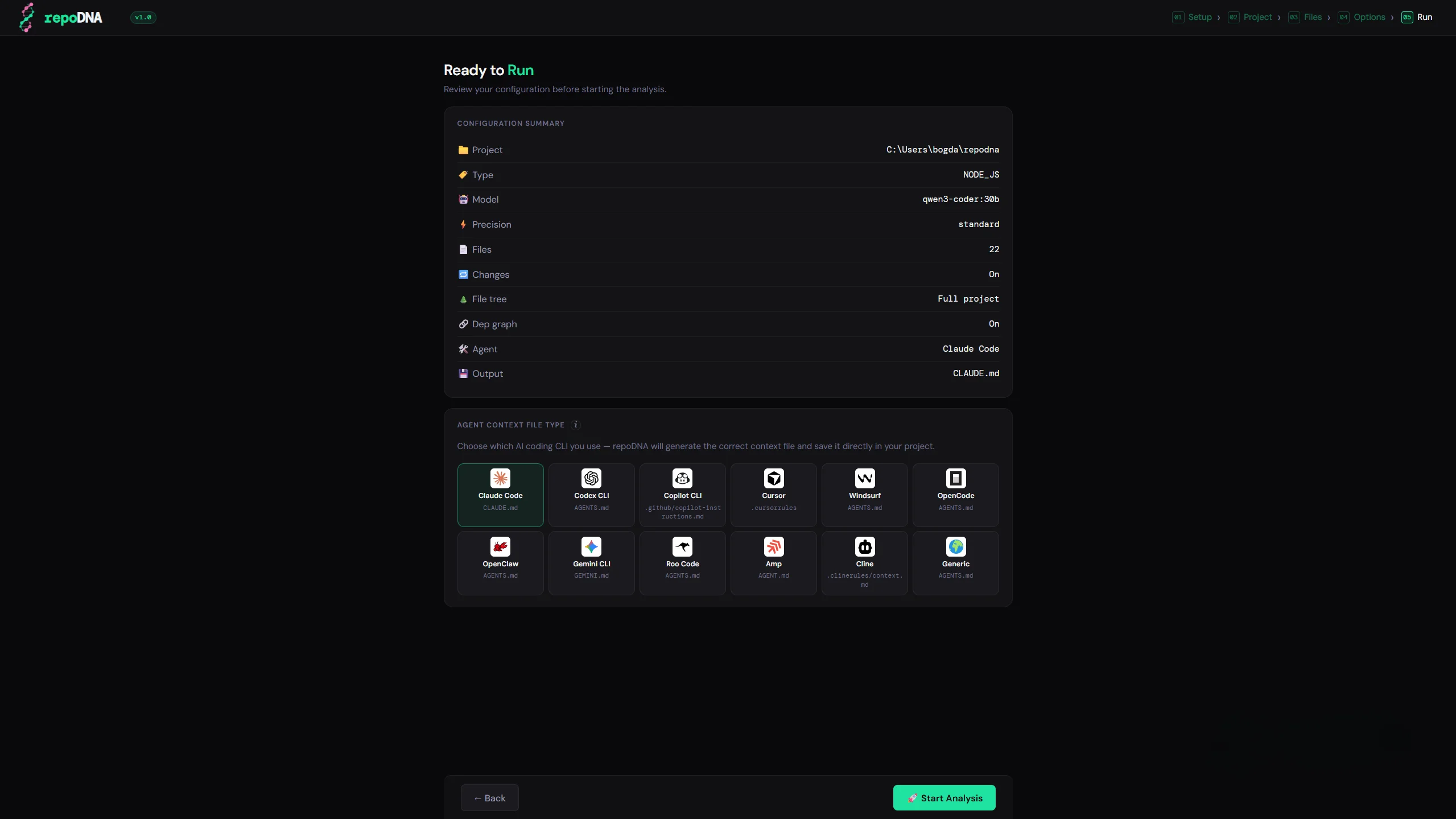
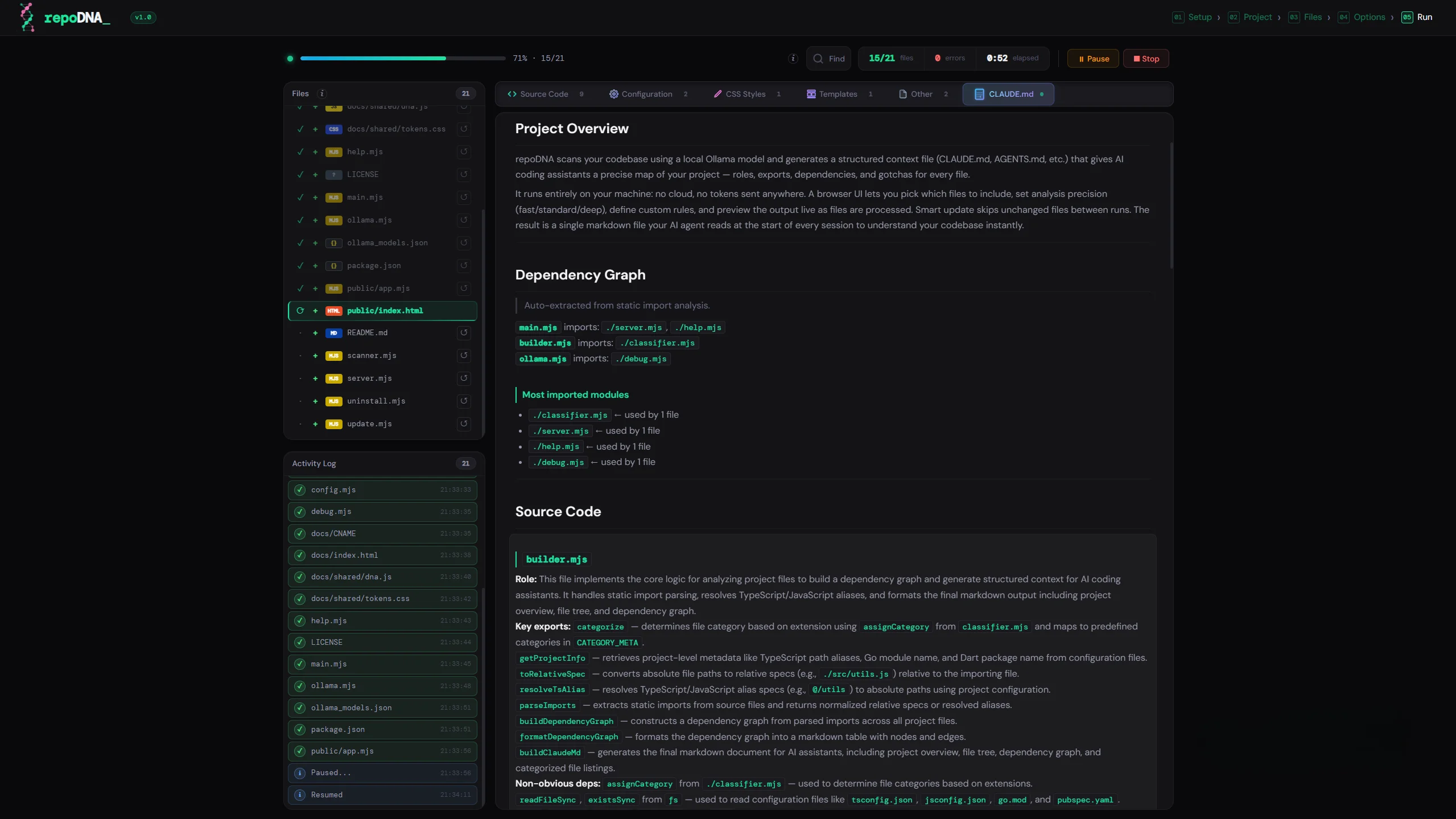
Every new AI session starts with no memory of your project. You end up re-explaining the same things every time. repoDNA fixes this — it scans your codebase and generates the context file your assistant reads at startup, so it already understands your project from the first message.
$
git clone https://github.com/BogdanVasaiu/repodna
$
cd repodna && node main.mjs